散列表-下
LRU缓存淘汰算法
首先回顾一下如何使用链表实现LRU缓存淘汰算法。需要维持一个按照访问时间从大到小排列的链表,当缓存空间不足时,直接删除表头的元素即可。
当要缓存某个数据时,首先在链表中进行查找,当找到时,将该数据移动到表尾即可,未找到时,在表尾插入该数据。只用链表实现的LRU的查找时间复杂度为$O(n)$。
一个缓存(cache)系统主要包含以下几个操作:
- 向缓存中添加一个数据;
- 从缓存中删除一个数据;
- 在缓存中查找一个数据。
上述三个操作都涉及查找操作,因而如果只是用链表实现的话,时间复杂度为$O(n)$。但如果将散列表和链表两种数据结构组合使用,可以将三个操作的时间复杂度降低到$O(1)$。结构如下:
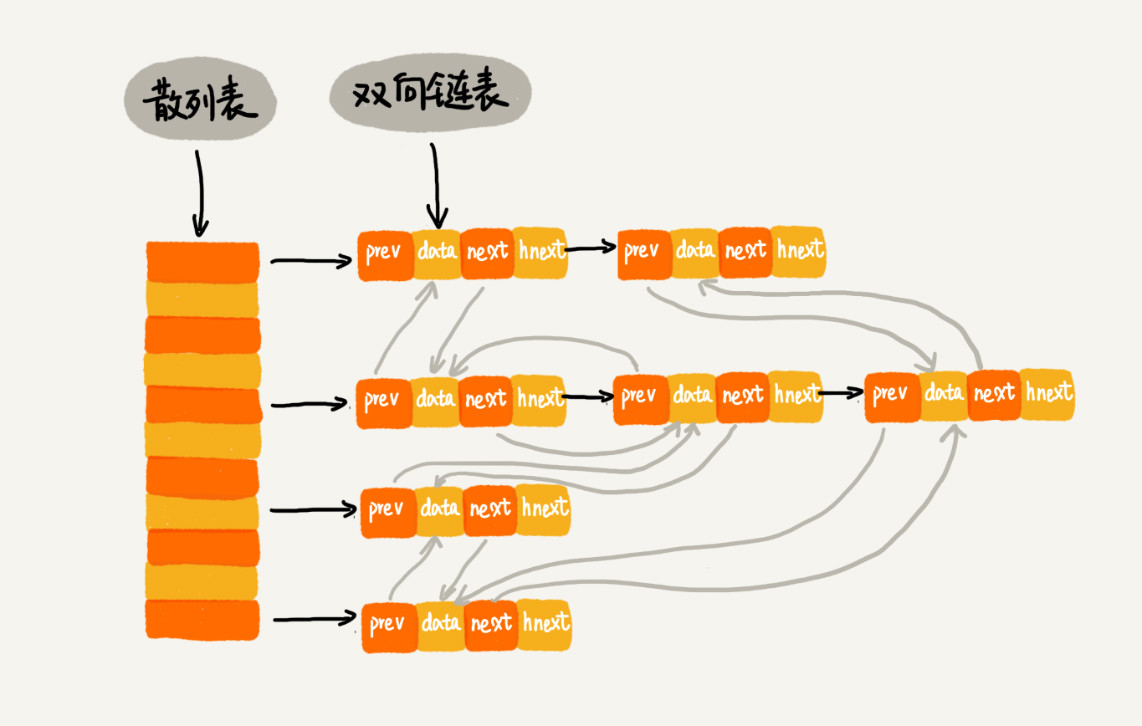
如上图所示,使用双向链表存储数据。链表中的每个结点除了数据(data)、前驱指针(prev)、后继指针(next)之外,还有额外的字段hnext。该字段的作用是将结点存放在散列表的拉链中。
在使用散列表进行查找时,使用链表法解决散列冲突。因而,除了将数据存储在双向链表中之外,还需要将数据存储在散列表的拉链中。前驱和后驱指针用于构成双向链表,hnext用于构成散列表的拉链。
那么,利用上述结构如何实现快速查找、删除和添加的操作?
当要查找一个数据时,利用散列表查找数据的时间复杂度接近$O(1)$的特性,可以很快查找到某一个数据;
当要删除一个数据时,可以使用散列表找到该数据,在利用双向链表删除该数据,查找数据的时间复杂度为$O(1)$,删除数据时,使用双向链表,时间复杂度同样为$O(1)$;当要添加一个数据时,需要首先查找该数据是否在缓存中,如果在则移至双向链表的尾部,如果不在且缓存已满则首先删除双向链表头部的结点,接着将数据放在链表的尾部,如果不在且缓存未满,则直接将数据放在双向链表的尾部。
上述所有过程中的查找操作都可以使用散列表完成,且删除头结点、链表尾部插入数据等都可以在$O(1)$的时间复杂度内完成。因而,三个操作的时间复杂度都是$O(1)$。
Redis有序集合
在有序集合中,每个成员对象有两个重要的属性:key(键值)和score(分值)。不仅可以使用score查找数据,还可以使用key查找数据。
例如,用户积分排行榜有如下功能:通过用户的ID查找积分信息,或通过积分区间查找用户ID或姓名信息。
因而,Redis中的有序集合就设计如下的操作:
- 添加一个成员对象;
- 按照键值删除一个成员对象;
- 按照键值查找一个成员对象;
- 按照分值区间查找数据,例如查找积分位于[100, 356]之间的成员对象;
- 按照分值从小到大排序成员变量。
假如我们仅仅按照分值将成员对象组织成跳表的结构,那么按照键值查询和删除成员对象将变得很慢。为了解决这个问题,可以模仿LRU淘汰算法的实现思想。使用散列表和跳表来保存数据。按照键值构建散列表,这样按照键值进行查找和删除成员对象的时间复杂度将变为$O(1)$。
Java LinkedHashMap
观察如下代码,会以何种顺序打印3、1、5、2这结构键值?
1 | HashMap<Integer, Integer> m = new LinkedHashMap<>(); |
结果是:上述代码会按照数据的插入顺序依次打印键值。那么,如果散列表中的数据是经过散列函数打乱之后无规律存储的,为何可以按照数据的插入顺序遍历打印?
实际上,LinkedHashMap也是通过散列表和链表结合在一起实现的。实际上,除了支持按照插入顺序遍历数据,还支持按照访问顺序遍历数据。
1 |
|
上述代码的输出为1、2、3、5。
每一次调用put()函数向LinkedHashMap中添加数据时,都会将数据添加到链表的尾部。前四个添加操作完成后,链表中的数据如下所示:
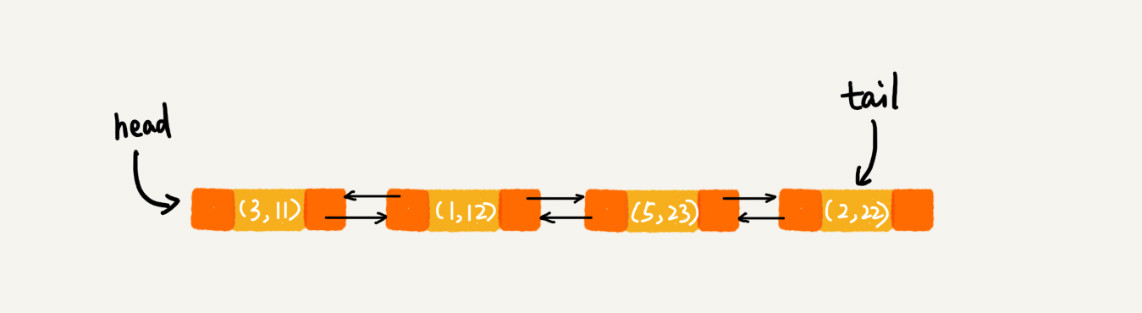
当实行m.put(3, 26)时,会首先对链表进行查找,如果存在该数据,则将链表中的数据删除,将新数据插入链表的尾部。
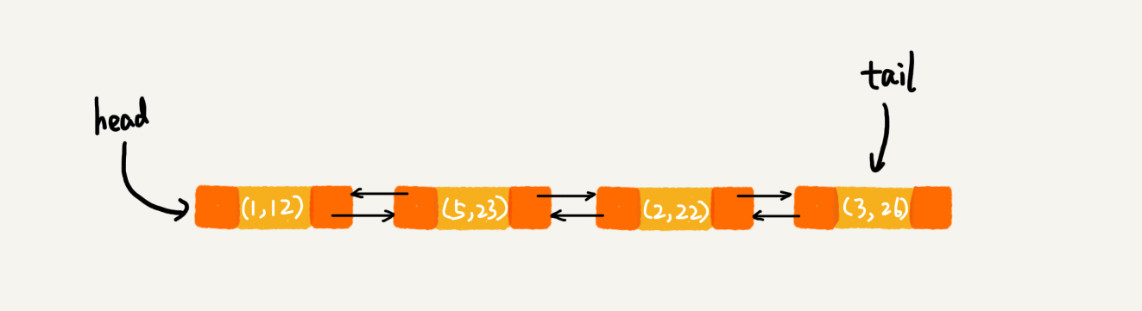
当执行m.get(5)时,则将被访问到的数据移动到链表的尾部。
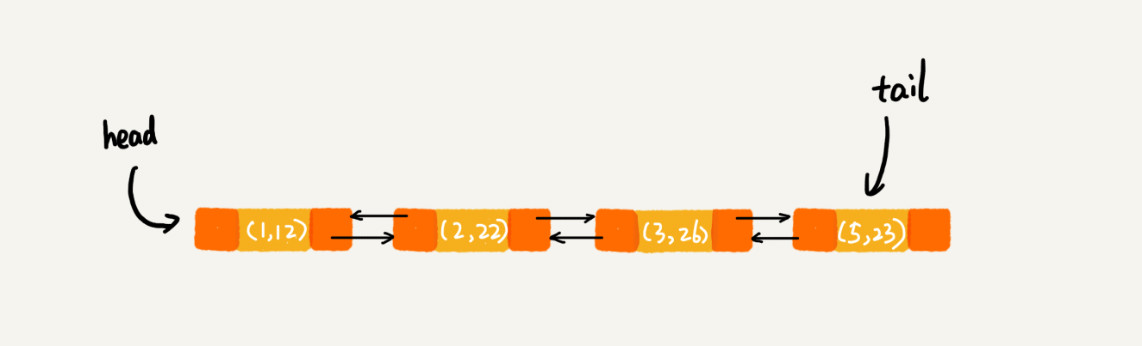
因而,最终执行打印语句时,输出的是1、2、3、5。
总结
为什么经常将散列表和链表组合使用个?
散列表虽然支持高效的数据插入、删除和查找操作,但由于散列表中的数据是通过散列函数打乱之后无规律存储的。因而,散列表无法支持按照某种顺序快速地遍历数据。因此,为了解决数据的顺序问题,常将散列表和链表(或跳表)结合在一起使用。