Kaggle-钢铁损伤检测总结
赛题
在这次比赛中,我们需要从官方提供的钢铁照片中使用语义分割方法对损伤部位的区域和类别进行检测。可视化示例如下:
类别1

类别2

类别3

类别4

总计有四种类别的损伤。
名次:Top4%。
数据分析
在进行数据分析时,主要关注以下几个方面:
类别间样本数目的比例
如下图所示,表示每一类损伤所拥有的样本的数目。

可以看出,第三类的样本数目最多,第一类和第四类差不多,第二类最少,类别不平衡问题比较严重。
单张样本包含的掩膜类别个数

大部分样本只包含一种掩膜或没有掩膜,只有很少的一部分有两种掩膜,不存在包含三种掩膜的样本。
有掩膜和没有掩膜的样本的比例
| 有掩膜 | 无掩膜 | 比例 |
| :——: | :——: | :——: |
| 6666 | 5902 | 1.13:1 |有掩膜的样本和无掩膜的样本的比例接近1:1。
方案
整体框架
在解决语义分割问题时,常用的基础方案是:在unet+resnet的基础上进行魔改。
本次比赛,我们主要使用模型架构是:分类加分割,整体模型架构如下图所示:
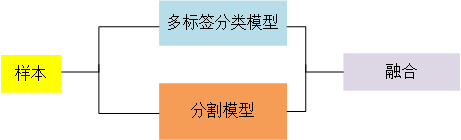
主要使用的模型结构有以下三种:
- Unet+Resnet34
- Unet+Resnet50
- Unet+SE-Renext50_32X4d
三个模型采用相同的策略:
- 首先截取Unet的编码网络,在其输出特征图的基础上添加额外的卷积层搭建分类网络。分类网络主要解决的是一个多标签的分类问题。使用分类网络我们可以区分出样本中所包含的损伤类别数目,将分类输出与分割模型的输出进行融合得到最终的检测结果。
- 只在有掩膜的样本上对分割模型进行训练。实验发现,这一做法优于在所有样本上训练分割模型,使用这一方法训练的分割模型会检测出偏多的掩膜。检测出的假正样本交给分类网络过滤。
数据增强
数据增强在应对模型过拟合和类别不均衡方面有很大的作用。主要使用的数据增强方法有以下几种:
- 水平翻转
- 垂直翻转
- 随机偏移
- 随机旋转
- 直方图均衡化
- 亮度、对比度调整
- 少量的模糊和噪声
测试时数据增强
使用测试时数据增强可以帮助模型降低预测方差,我们使用的增强方式有以下三种:
- 原图
- 水平翻转
- 垂直翻转
在对三者的分割结果进行结合时,采用平均的方式。
数据集划分
采用分层划分的方式划分为5折,使用其中的四折进行训练,一折作为验证集用于在训练过程中保存最优模型。在使用不同的折训练模型时,我们发现不同折所得到的模型在公开排行榜上的分数有着较大的差距。其原因应该是各折之间各类的样本数目不平衡。
模型集成
在进行模型集成时,我们采用了两种集成方法:平均和投票法,经过实验测试,投票法优于平均法。
结果
在此次比赛时,取得了Top 4%的排名。与公有榜的排名相比,私有榜的排名波动非常大,在公有榜排名第一的大佬,在私有榜掉到了70多名。我们的名次却前进了近300名,这也说明我们的模型在应对过拟合时有着较好的性能。
可视化
可视化结果如下:


结论
其实,并没有完全发掘出三个模型的潜能,除了数据集划分问题外,主要是未解决好类别不均衡问题和对正样本的识别。
模型能够较为正确地识别出负样本,但对正样本的识别能力较差。推测,私有榜使用的测试样本中应该含有大量的第三类正样本,而由于模型对正样本的性能预测不足,因而在这一类上性能较差,而对于其它类来说,因为模型能够正确地识别出负样本,其它三类的负样本占比较多,因而其它三类的评分较高。
这一点可以从排行榜的浮动上看出,公有榜的最高分数超过了0.92,而私有榜的分数未超过0.91。说明大家的模型对第三类正样本的识别存在一定的问题。
下图依次是公有榜和私有榜前几名的分数:
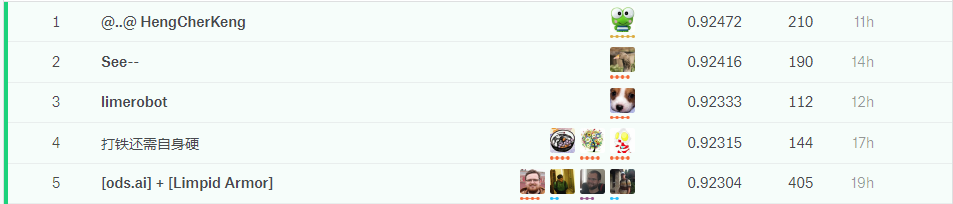
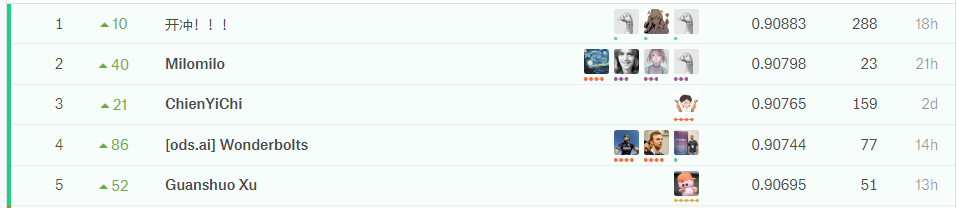
可以看出,奖金池中的队伍完全变了样。
在调节模型参数的过程中走了一些弯路,比如没有依据数据分析结果调整类别损失间的权重;一开始没有完全解决数据集的划分问题,导致后期时间不足没有时间调整。未分析出模型表现不良的真正原因。
Tried But Not Work
我们还尝试了以下几个策略,但都未带来性能的提升:
- 对输入图片进行随机裁剪,裁剪大小为$256\times400$,预测使用原始图片大小。
- 使用EfficientNet网络作为分割模型的编码器(可能是由于模型计算量较大,batch_size太小,未训练好)。
- 使用加权二维交叉熵+BCE损失。损失函数的确很难调整,但的确是解决类别不平衡问题的有效方法,没有效果的原因可能是权重比例设计不对,应该依据数据分析的结果进行设置。
代码
我们的代码位于:Code。