如何构建SSD目标检测网络?
这是一篇翻译文章,原文链接。
思想
在深度学习模型中,随着深度的增加特征图的大小逐渐降低。深层的网络具有更大的感受野,同时具有更为抽象的表示能力,而浅层的感受野相对较小。在目标检测中,因为小的目标不需要更大的感受野并且更大的感受野会使得模型在检测小目标时变得混乱,因而可以使用模型的浅层来预测小目标,深层来预测大目标。
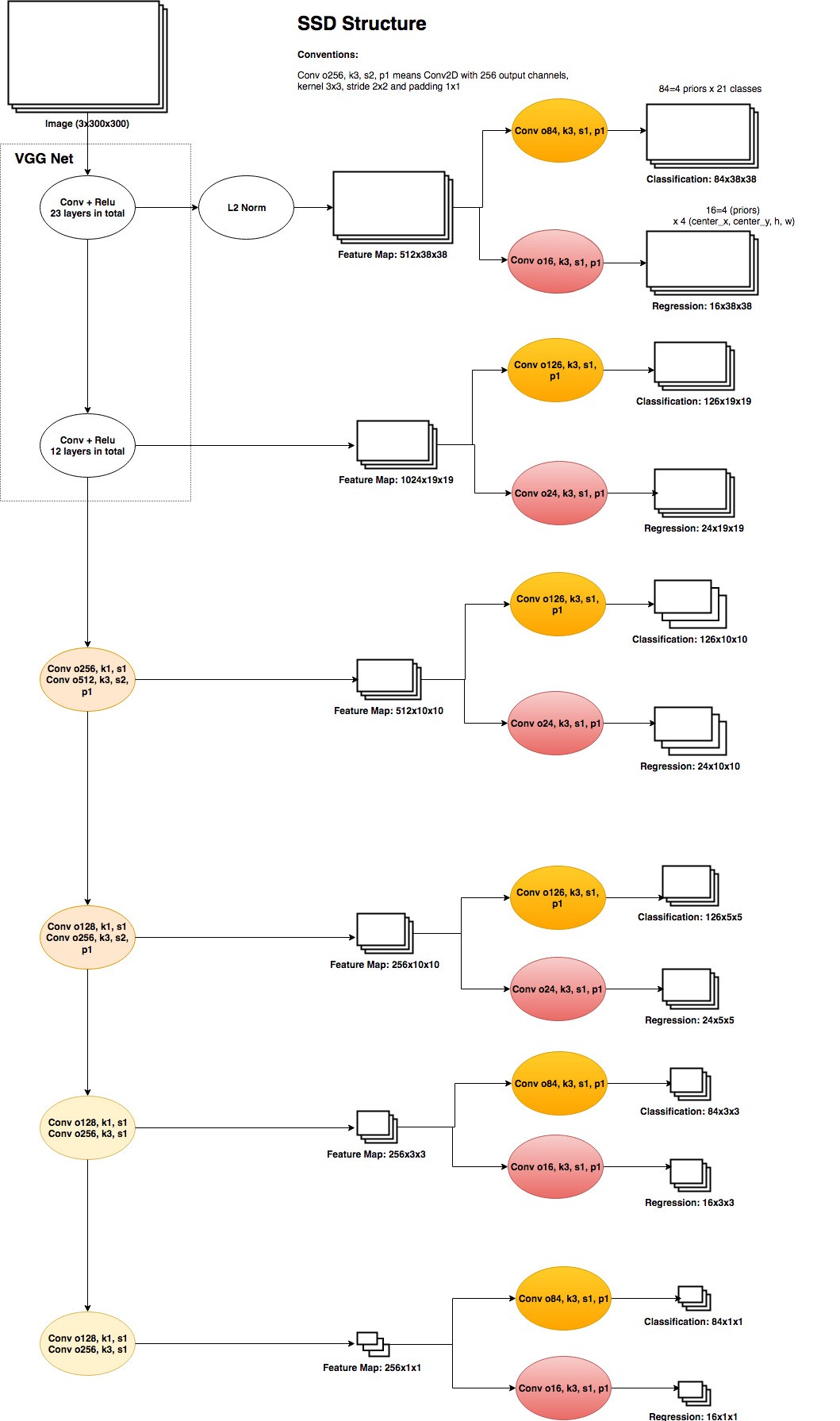
下表展示了使用VGG作为basenet的SSD网络的结构。中间一列展示的是由不同层产生的特征特。例如,第一层特征图由VGG的第23层产生,特征图大小为$38\times38$,深度为512。$38\times 38$大小的特征图中的每一个点都覆盖了图片的一部分,512个通道可以被视作每一个点的特征。通过使用512个通道中的特征,我们可以对每一个点使用图片分类来预测类标以及使用回归来预测小目标的bouding box。第二层特征图的大小为$19\times19$,该层的每一点有着更大的感受野,因而可以被用于检测稍大的目标。而对于最后一层特征图,只有一个点,因而该层被用来检测最大的目标。
以Pascal VOC数据集为例,总共有21类(20个目标类和一个背景类)。需要注意的是,对于每一个特征点的分类结果来说总共有$4\times24$个输出。4表示每一个点总共预测4个不同的bounding boxes。在SSD中,每一个特征图中的多个boxes被记作priors,而在Faster RCNN中被称为anchors,两者实际上是同一个概念。
训练
生成Priors
对于特征图中的每一个点,我们都会生成一些priors,这些priors将被用于和ground truth的标定框进行匹配来决定类标和bounding boxes。
产生priors的代码如下:
1 | import collections |
将Priors与Ground-Truth进行匹配
当我们将priors和ground-truth标定框进行匹配后便可以得到训练目标。Prior和ground-turth标定框进行匹配的评价准则是IoU(Intersection Over Union),或者被成为Jaccard Index。IoU越大表示两个框的重合度越高。匹配的流程如下:
1 | for every ground-truth box: |
首先,对于每一个ground truth都匹配一个prior;接着,对每一个prior都尝试匹配一个ground truth。
尺度化Ground-Truth标定框
为了更好地训练,需要将ground-turth标定框进行尺度变换,将其表示在同一尺度内。在SSD中,转换方式如下:
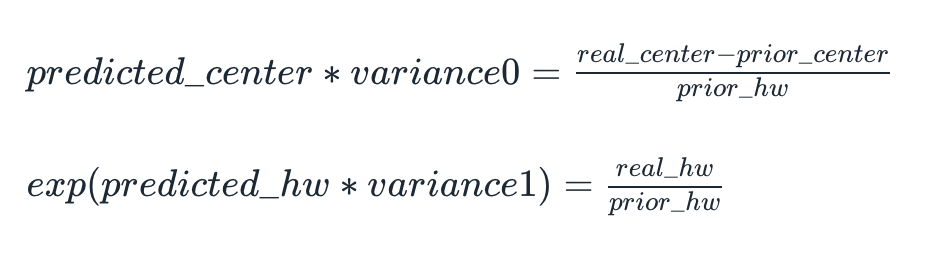
在论文中,variance0和variance分别被设定为0.1和0.2。
难例挖掘
在上述匹配策略中,我们通过将ground-turth与多个priors进行匹配来提升正目标(指那些被分配了真实目标的priors)。然而,仍旧存在大量的未匹配的priors。也就是说,这些被标定为背景类的priors会使得数据集极度不平衡。为了使得数据集变得平衡,可以使用难例挖掘策略。难例挖掘的思想在于,在计算整体的损失函数时,只考虑那些置信度最高的几个背景类priors,其他置信度较低的背景类priors则被舍弃。这样一来,背景类priors和匹配的priors之间的比例就变得相对较低(文章中设定为3)。
损失函数
损失函数由分类损失和回归损失结合而成。这里的回归损失使用的是$Smooth-L1$损失,该损失和Faster RCNN和Fast RCNN中使用的一样。
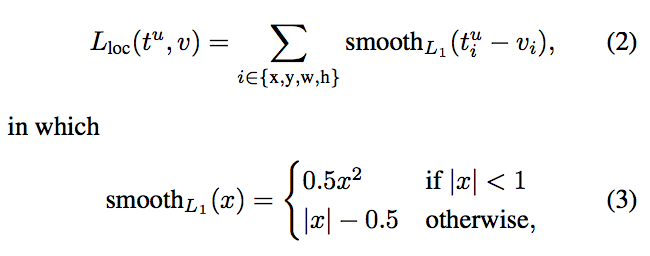
数据增强
使用数据增强可以帮助网络学习数据中的不变性。与Faster RCNN不同,数据增强在SSD中有着重要的作用。使用的数据增强如下所示:

预测
预测过程比较简单。将图片送入网络,每一个prior都会有预测出的一系列的bounding boxes和labels。在计算过程中,我们可能将一个目标分配给了多个priors,因而会有多个priors预测同一个目标。为了移除重复的目标,需要使用非极大抑制方法。
NMS
NMS只保留有着最大概率的bounding boxes,移除有着更低概率和与留下的bounding boxes有着更大的IoUs的那些bounding boxes。伪代码如下:
1 | for each class: |
不足之处
网络中较浅的层可能无法产生足够高层次的特征来对小目标进行检测,因而SSD在小目标上的性能比大目标差。
需要对训练数据进行复杂的增强表明训练需要足够多的样本数目。例如:如果在COCO数据集上进行预训练,那么在Pascal VOC上会得到更高的性能。所以在将模型用于自己的数据集之前,要确保模型在大数据集上进行过预训练。
Prior boxes的设计是一个开放问题,需要额外注意。