EfficientDet: Scalable and Efficient Object Detection
为了得到高效率的目标检测算法,人们提出了很多研究。例如:
- one-stage目标检测算法:YOLO系列等;
- anchor-free目标检测算法:CornerNet等;
- 对现有的模型进行压缩:模型剪枝、量化等。
但是这些方法都会损失一定的精度,同时,这些方法都集中在特定或者小范围的资源限制上,难以应对不同的现实生产环境之间较大的资源差别。
为此,该文章提出了一个问题:是否可以设计一个可变的目标检测结构,该结构有着更高的准确度,同时能够应对较大跨度的资源变化?
为了解决这个问题,本文系统性地研究了设计目标检测结构时的不同设计选择。在one-stage检测流程的基础上,作者测试了backbone、feature fusion和class/box网络的不同设计选择。并总结出了如下两个挑战:
- Challenge 1:高效的多尺度特征融合。特征金字塔网络(FPN)被广泛应用于cross-scale特征融合。在进行特征融合时,之前提出的方法只是简单地对这些不同尺度的特征进行相加。但是,由于这些特征具有不同的尺度,因而对最终的融合特征的贡献也是不同的。为了解决这个问题,作者提出了一种简单但有效的方法:加权双向特征金字塔网络(weighted bi-directional feature pyramid network, BiFPN)。该网络使用可学习参数来学习不同输入特征的重要性,并反复使用自顶向下和自底向上的特征融合方法。
- Challenge 2:模型尺度。之前的网络要么使用更大的backbone网络、要么使用更大的输入图片尺寸来提高准确率。但作者发现,提升特征网络和box/class预测网络的尺度同样很重要。因而,作者提出了一种针对目标检测算法的复合尺度方法。该方法同时对所有backbone、feature network以及box/class预测网络的尺度进行调整。
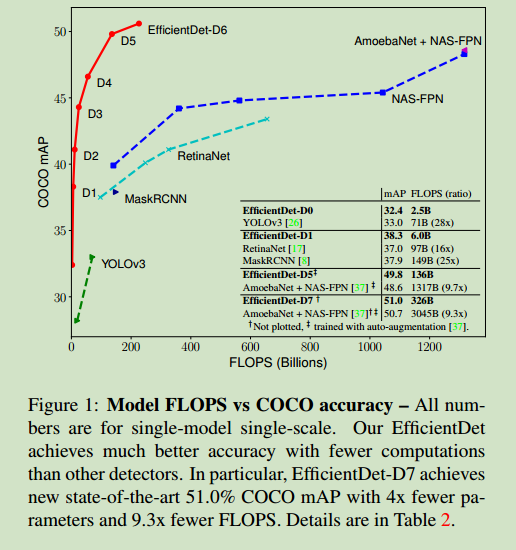
- 最后,作者发现将EfficientNet和上述两种方法进行调整,得到一种称为EfficientDet的网络模型,该模型在取得更高的准确率的同时,参数更小、FLOPS更小。该网络的FLOPS比YOLOv3小28倍。其版本之一EfficientDet-D7在只有52M参数和326B FLOPS的同时,在COCO上取得了最高的51.0的mAP。
相关工作
- one-stage目标检测算法:本文主要基于one-stage目标检测算法进行改进;
- 多尺度特征表示:目标检测的主要挑战之一便是如何高效地表示和处理多尺度特征。之前,已经有类似于FPN、PANet、M2det、NAS-FPN等工作尝试解决这一问题。在本文中,作者尝试以一种更加符合直觉和有原则的方式进行特征融合。
- 模型尺度:大多数模型尺度调整方法大多集中于单个尺度。在本文中,作者对网络中的多个尺度都进行了调整。
BiFPN
首先,作者对多尺度特征融合(multi-scale feature fusion)问题进行了问题定义。多尺度特征融合的目的是将不同分辨率的特征进行融合。
给定一些列的多尺度特征$\vec P^{in}=(P_{l_1}^{in},P_{l_2}^{in},…)$,其中$P_{l_i}^{in}$表示$l_i$级的特征,目标在于使用转换$f$对不同尺度的特征进行融合。
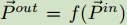
以FPN(下图中的图a)为例,使用了一种自顶向下的方式进行多尺度特征融合:
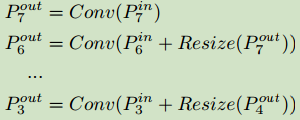
为了进行特征匹配,常使用上采样和下采样操作对特征图进行上采样或下采样。
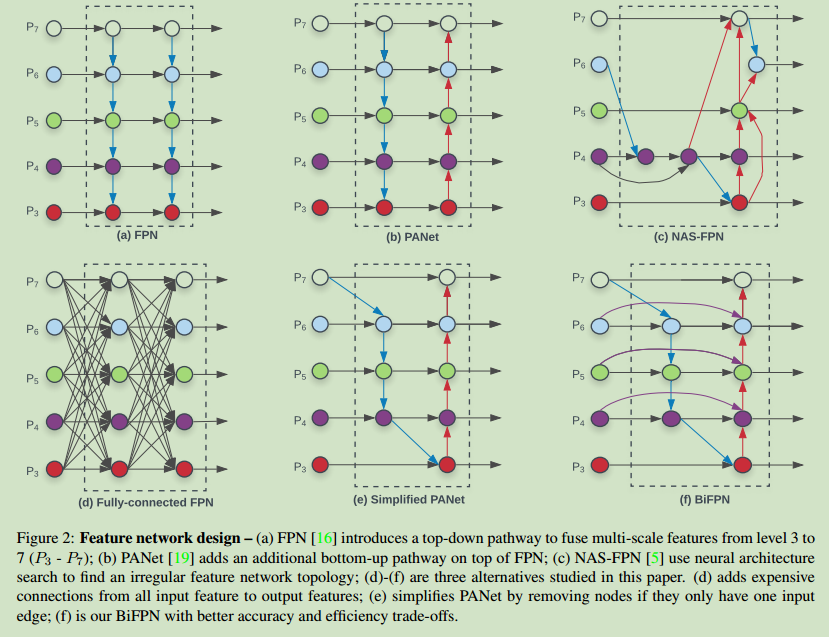
为了解决FPN只要一条信息流的问题,PANet网络引入了一条自底向上的融合网络,如上图中的图b所示。同时,也有使用网络结构搜索方法来解决特征融合问题的方法,但既耗时又缺乏可解释性。
作者研究发现,相比于FPN和NAS_FPN,PANet有着更高的准确度但参数更多。为此,作者进行了一些优化,首先移除了只有一条输入边的节点(对于多尺度特征融合网络来说,只有一条输入边的节点贡献很小),结果如上图的e所示;接着,在原始输入节点和输出节点之间(有着同样的尺度)添加了一条边(如上图的f所示);最后,PANet中只有一路自底向上和一路自顶向下的路径,而在本文中,将每一个双向(top-down和bottom-up)的路径看做一层特征网络层。并重复同一层多次来获得更多高层次的特征融合。结构如下所示:
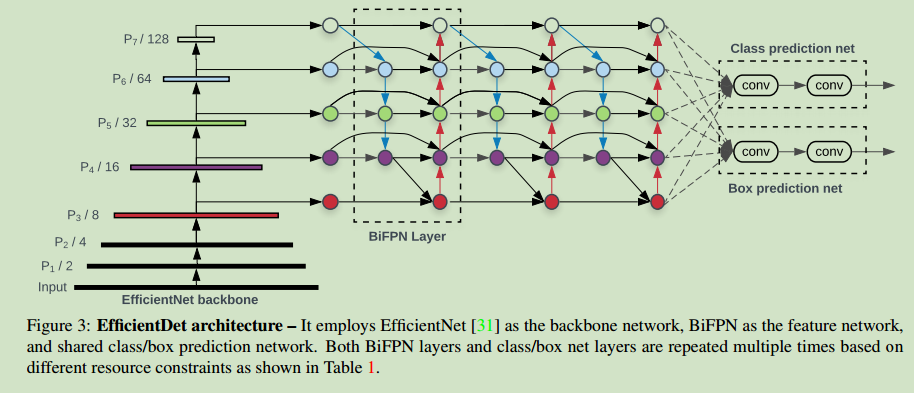
在之前的特征融合方法中,将各个输入特征同等对待。但实际上,不同尺度的特征具有不同的贡献。为此,作者给不同尺度的特征赋予了不同的权重,并在训练过程中对这些参数进行学习。有以下三种加权方法:
无边界融合:$O=\sum_i w_i \cdot I_i$,每一个权重可以是一个标量(每一个特征图一个权重)、一个向量(每一个通道一个权重)、多维张量(pre-pixel),作者发现标量已经可以取得比较好的性能。同时,如果不对权重进行限制,会导致训练不稳定,因而,对权重进行了归一化。
基于softmax的融合:
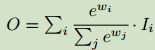
使用该方法可以将权重限制在[0,1],但是softmax会拖慢GPU的计算。
快速归一化融合:
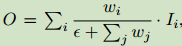
为了确保每一个权重大于0,对每一个权重进行ReLU激活。这一版本的融合方法运行速度更快。
最终的BiFPN网络同时使用了双路cross-scale连接和快速归一化融合方法。如下例:以等级6的特征图融合为例:
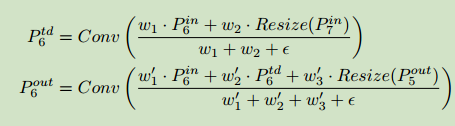
其中,$P_6^{td}$是位于等级6的top-down支路的中间特征,$P_6^{out}$是等级6的bottom-up支路的输出特征。为了进一步提高效率,使用深度可分离卷积来进行特征融合,并在每一层卷积层后都添加BN和激活层。
EfficientDet
网络结构
在BiFPN的基础上,作者提出了EfficientDet结构,如Figure 3所示。以在ImageNet上预训练的EfficientNets为backbone,重复使用top-down和bottom-up双路特征融合模块对多尺度特征进行融合。接着将这些融合后的特征送入class和box网络来预测最终的目标类别和bounding box。所有尺度的特征共享相同的class和box网络权重。
复合尺度
为了优化准确度和效率,作者设计了一些列的适合于不同资源限制的网络结构。主要挑战是对baselin EfficientDet模型进行尺度化。
作者受EfficientNet的启示,设计了一个复合系数$\phi$对backbone网络、BiFPN网络和class/box网络的所有维度(深度、宽度、输入尺寸等)同时进行尺度调整。
与分类网络相比,目标检测网络需要调整的维度更多,因而无法使用栅格查找法进行搜索,为此,作者使用了一种启发式尺度化方法。
Backbone network:为了使用EfficientNet的预训练权重,作者使用与EfficientNet-B0到B6相同的深度、宽度系数。
BiFPN network:作者对BiFPN的宽度$W-{bifpn}$采用指数级增加的方法,而对深度$D_{bifpn}$采用线性增加的方式(深度需要四舍五入到小整数):
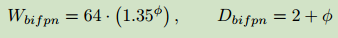
Box/class prediction network :将这一部分的宽度固定为和BiFPN相同,对深度依据下式进行线性增加:
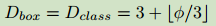
输入图片的分辨率:因为选中的多尺度特征图的大小问题,输入图片的分辨率必须可以被$2^2=128$整除,因而,依据下式对分辨率进行线性提升:

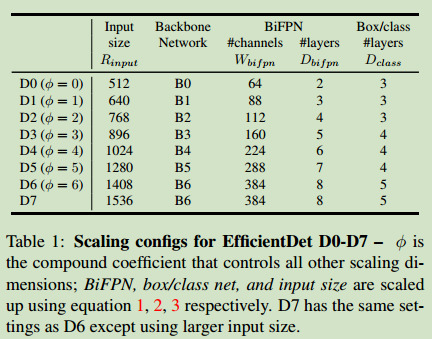
对上述等式中的$\phi$设定不同的值,便可以得到不同规模的EfficientDet网络。如下标所示:
实验结果
数据集:COCO 2017目标检测数据集
训练策略:
优化器:
使用SGD优化器,momentum为0.9,权重衰减为4e-5。
学习率:
在前5%epoch使用warm-up策略从0提升到8e-2,后续使用余弦退火算法进行学习率衰减。
BN:
每一层卷积后都加了BN,衰减为0.997、epsilon为1e-4。使用衰减为0.9998的指数滑动平均。
损失函数:
Focal loss,$\alpha=0.25$,$\lambda=1.5$。
实验结果如下:
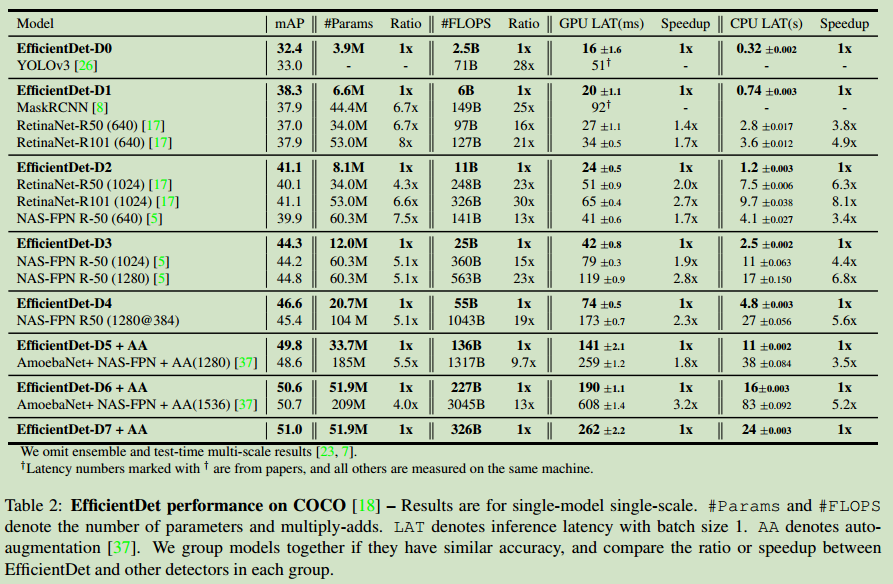
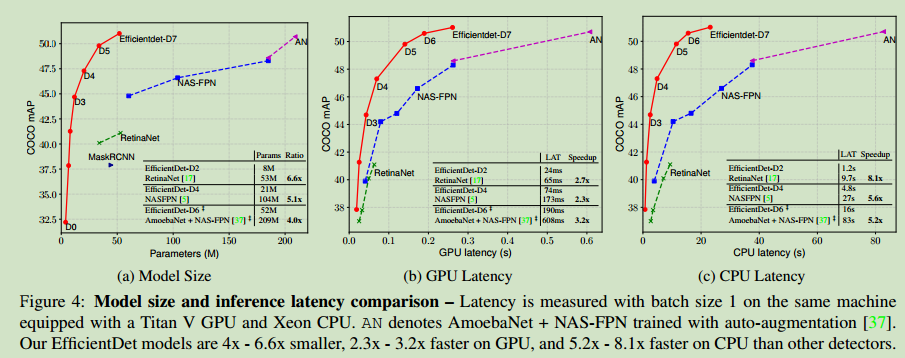
模型大小和推理能力的比较:
个人评价
具体实验还没有实地跑过,但因为backbone使用的是EfficientNet,因而可能对显存要求比较大。