图像比赛常用Tricks
图像数据增强
训练时数据增强
在图像比赛中,常遇到数据不足的情况,这一问题很容易导致模型的过拟合,解决该问题的方法除了有调整模型的参数容量之外,也可以通过数据增强的方式进行解决。
- 亮度、饱和度、对比度的随机变换
- 随机裁剪(Random Crop)
- 随机缩放(Random Resize)
- 水平、垂直翻转(Horizontal / Vertical Flip)
- 旋转(Rotation)
- 模糊(Blurring)
- 加噪声
在进行数据增强时,增强后的数据应尽量接近原始数据的分布。
测试时数据增强( test time augmentation, TTA)
在进行测试时,也可以进行数据增强。对一张测试样本,使用数据增强方法增强后再进行预测,最后再将预测的结果进行平均。使用TTA可以使模型的预测更加平稳。
交叉验证
在进行模型训练时,我们一般会使用数据集中的一部分进行训练,剩余部分用作验证。通过对模型在验证集上的性能表现进行观察,可以确定模型是否过拟合或性能不再提升。
留一法交叉验证
这一方法将数据集划分为两个部分,选择数据集中的一个数据作为验证,用剩余的数据集训练模型,对每一个数据点都重复这个过程。
- 该方法使用了所有的数据点,偏差较低
- 验证过程重复了n次,导致执行施加很长
- 只使用一个数据作为验证,因而对模型的性能度量的差异较大。
K-Fold交叉验证
可以将数据集均分为K份,使用其中的K-1份对模型进行训练,剩余的1份用作验证。将这样的挑选过程重复K次,便可以得到K个模型,对K个模型的训练结果进行平均,作为在整个数据集上的训练结果。简要步骤如下:
- 将整个数据集划分为k份
- 用其中的k-1份作训练,剩余1份用作验证
- 记录每个预测结果的误差
- 重复k次,直到每折数据都被用于训练和验证
当k=10时,k-fold交叉验证示意图如下(示意图借鉴自eamlife’s blog):

交叉验证划分注意点
- 队伍内部共享同一个划分
- 单模型阶段和模型集成阶段尽量使用同一个划分
- 训练集和验证集的划分要和训练集与测试集的划分方式一致
- 折数划分越多会消耗更多的计算资源
- 数据量足够多时,可以不进行划分
k值越小,偏差越大,k值越大,偏差变小,结果波动变大,越不稳定。K值一般选择在5~10之间。
分层k-折交叉验证(stratified k-fold cross validation)
在原始的k-折交叉验证中,折的划分是随机的,这种做法会导致原始数据集中的各个类别之间的比例被打乱。使用不同折训练得到的模型差异较大。分层k-折交叉验证的目的就是保证在每一折中都保持原有的类别比例,如下图所示(借鉴自eamlife’s blog)。
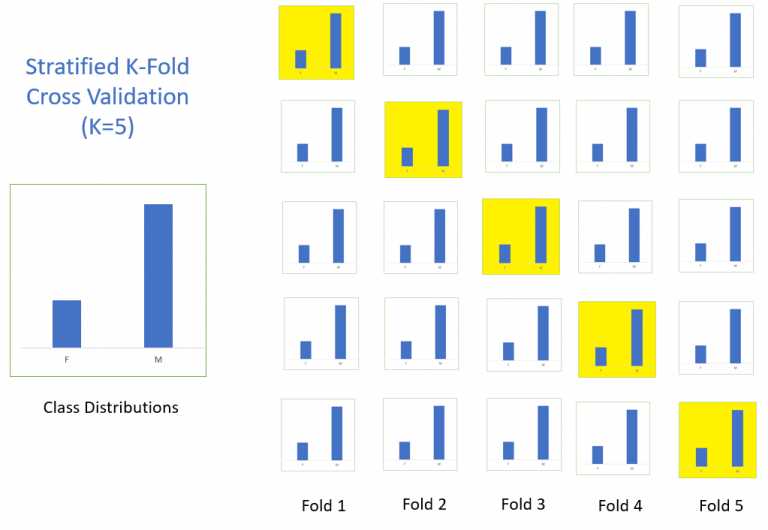
当出现数据不平衡问题时,常使用这一验证方法。
自助法
基于划分训练集和测试集的方法进行模型评估的方法,在数据集规模本身较小的情况下会让训练集进一步减少,可能会影响模型的训练效果。为了维持训练集样本规模,可以使用自助法。
自助法是基于自助采样法的检验方法。对于总数为n的样本集合,进行n次有放回的随机抽样,得到大小为n的训练集。有些样本会被重复采样,有的样本没有被抽出过,将没有被抽出的样本用作验证集。
模型集成
所谓模型集成,即使用多个模型的预测结果综合得出最终的预测结果。所有训练过的模型都存在不同程度的过拟合,进行模型集成会带来不小的性能提升,在进行模型集成之前需要训练好多个性能良好的模型。
平均打包(average bagging)
以分类问题为例,对于给定的单样本,每个模型都会给出其分属于各个类别的预测值。对于所有模型的预测结果施加相同的权重,最后进行平均,得到最终的预测结果。

打包集成选择(bagging ensemble selection)
在这一集成方法中,给每一个模型赋予不同的权重。首先,进行模型选择,在选择的过程中,有的模型可能被选中多次,有的模型可能一次也没被选中。完成模型的选择后,按照模型被选中的次数计算各个模型的权重,依据该权重对模型的预测结果进行加权平均得到最终的预测结果。

Stacking
在这一集成方法中,对每一个模型的每一个类都赋予不同的权重,例如,有的模型在A类上的预测性能较好,在其他类上的预测性能较差,因而需要给A类赋予更高的权重,其他类赋予较低的权重。