Universally Slimmable Networks and Improved Training Techniques
这篇论文是Slimmable Neural Networks的升级版,在Slimmable Neural Networks中,作者提出了一种可以依据不同的运行资源限制选择具有不同宽度的网络模型的方法。但有一个很明显的限制,只能从事先定义的宽度集合中选取特定的宽度,本文便是针对这一限制进行改进。
本文提出的网络可以运行在任意的宽度,并且可以应用于有或者没有BN层的网络结构。为了达到这一目的,作者首先思考了基本的特征聚合的方式。
在深度网络中,一个神经元的输入来自于前一层的多个神经元。也就是说,可以将这多个神经元中的一个通道或者多个通道看作一个残差块(在何凯明的论文中提出)。进一步,相对于窄的网络,一个宽的网络只会有着更好的性能(在宽网络中,只要将相对于窄的网络的输出学习为0即可达到和窄的网络同样的输出)。
考虑单独的一层,全聚合和部分聚合之间的残差误差随着宽度的增加而降低,并且存在上界和下界,如下式所示:

其中$y^k$表示前$k$个通道。
为了得到可以以任何宽度运行的网络,需要解决如下问题:
- 如何处理BN层。
- 如何高效训练U-Nets网络。
- 与训练单个网络相比,如何提升整体的性能。
对于BN层来说,Slimmable Neural Networks中采取的方法是对不同的分支维持不同的BN参数,但这一做法对于U-Nets是无效的,原因在于:
- 计算量太大。
- 如果在每一代迭代时只更新一些被采样到的子网络,这些BN参数会被不必要的累加,进而降低准确性。
为了解决这一问题,采用在训练完成后计算所有宽度的BN参数的方法。
在进行网络的训练时,由于在US-Net中,所有宽度的性能都在最大宽度和最小宽度之间,因而只需要对上界和下界的模型进行参数优化就可以更新所有宽度的模型。因此在训练过程中,作者只对最小宽度、最大宽度和(n-2)个随机采样的宽度进行了训练。
进一步,作者提出了本地蒸馏的训练思路,在每一轮训练过程中使用最大宽度的模型的类别输出作为其它模型的训练类标。

上图为使用不同宽度的网络。
实现细节
重新思考特征聚合(feature aggregation)
神经元对所有输入神经元进行加权求和以完成特征聚合的目的,表示为下式:
其中,n是输入神经元的数目(卷积神经网络中的通道数),$x={x_1,x_2,…,x_n}$是输入神经元,$w=w_1,w_2,…2_n$是可学习参数,$y$是单个输出神经元。这一过程也被称为特征聚合:每一个输入神经元负责特定的特征,输出神经元使用可学习参数对所有的输入神经元进行聚合。
如上图所示,特征聚合可以被解释为通道级的残差学习,对于输出神经元来说,输入神经元中的一个或一组都可以被看作一个残差模块。
可以将残差误差表示为下式:
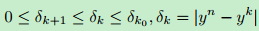
上式提供了以下猜测:
- 运行在离散宽度的Slimmable network可以运行在其选取的宽度区间之内的任意值(前提是被正确训练)。也就是说,单个网络可以运行在$k_0$到$n$之间的任意网络宽度,因为残差误差存在界限,并随着宽度的增加而降低。
- 理论上,有界不等式适用于任何形式的神经网络,不论采用了哪一种归一化层。
BN层的后统计
因为训练和测试过程中的不持续性,BN层需要被特殊处理。在训练过程中,每一层使用当前mini-batch特征图的值$x_B$的均值和方差进行标准化:
其中,$\epsilon$被用于防止除数为0。$\lambda$和$\beta$是可学习的尺度因子和偏移因子。特征的均值和方差被使用滑动平均的方法更新到全局统计值,即使用过往的值和当前批次的值进行加权求和:
假设$\mu=\mu_T$,$\sigma=\sigma_T$,$T$表示经过$T$轮迭代。那么,在进行前向传播时,使用全局统计值分别替代均值和方差:
其中,尺度因子和偏移因子为学习得到的最优参数。在完成训练后,可以将上式转换为线性变换:
并且,上式中的乘子和偏移可以被进一步融合进上一层卷积层。
在上面的论述中,在测试时使用的参数都是训练参数的统计值。而在本文的方法中,测试时使用的BN层参数是通过在训练完成后重新计算的方式得到的。训练完成后,US-Nets中的可训练参数都是固定的,因而所有的BN统计值可以被并行计算得到。在训练完成后,可以在训练样本上计算BN层的统计参数,或者使用上述的滑动平均的方法,或者使用下述精确平均公式:
实验表明,精确平均性能更好。
提升训练技术
三明治规则(Sandwich Rule)
优化最宽和最窄的网络的参数可以达到优化宽度区间中所有网络的目的。因而三明治规则指的就是:在训练时,训练最宽、最窄和(n-2)个随机宽度,而不是直接训练n个随机采样的宽度。
原地蒸馏(Inplace Distillation)
原地蒸馏的思想是:在每一轮训练时使用将完整网络的知识迁移到其它子网络。
在US-Nets中,一次训练最宽、最窄和任意的n-2个宽度的模型。我们可以直接将最大宽的模型的预测类标作为其它宽度的模型的训练类标。
在实际操作中要注意,使用完整网络的输出计算子网络的损失时,要记得将完整网络的预测类标从模型中分离出来。以防止子网络损失的梯度传播到完整网络中。
训练流程
整体训练流程如下:

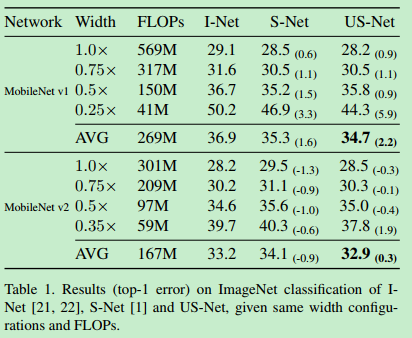
结果