Momentum Contrast for Unsupervised Visual Representation Learning (MoCo)
用于视觉表示学习的动量对比。
作者:Kaiming He 以及FAIR的一众大佬
简介
这篇文章主要解决的是无监督视觉表示学习问题。作者从将对比学习看做字典查找(dictionary look-up)出发,使用队列(queue)和滑动平均编码器(moving-averaged encoder)构建动态字典。这一做法使得通过在线构建大容量且协调的字典来实现对比无监督学习成为可能。作者表示,该方法在7种检测和分割任务上超过了有监督学习方法。
内容
在自然语言处理(natural language processing, NLP)领域,无监督学习已经取得了巨大的成功,但是在计算机视觉(computer vision, CV)领域仍旧以有监督学习为主。造成这一差距的原因在于,CV和NLP具有不同的信号表示空间,NLP的信号空间是离散的(words、sub-words units),这是有利于构建字典的;而CV的信号是连续、高纬度且对于人类通讯来说是非结构化的,这一特点不利于构建字典。
目前,已经有一些方法借助对比损失(contrastive loss)在无监督视觉表示学习领域取得了可观的成果,这些方法都可以被视作构建动态字典。字典中的键值从数据中采样得到(图片或patches),并使用编码网络对这些数据进行表示。无监督学习训练编码器进行字典查找:被编码的查询集应该与其所匹配的键值相似,而与其他的键值具有较大的差距。学习过程被表示为最小化对比损失。
从这一观点出发,作者认为所构建的字典应该具有以下的特点:
- 具有大容量;
- 在训练过程中保持前后一致。
原因在于:更大容量的字典有利于更好地对连续且高维度的视觉空间进行采样;同时字典中的键值应该使用相同或类似的编码特征进行表示,因而这些键值与查询集的对比是连续的。然而,当前使用对比损失的方法在这两点中的一点存在限制。
本文中提出的MoCo方法借助对比损失来构建大容量且协调的字典以处理无监督学习问题,如下图所示:
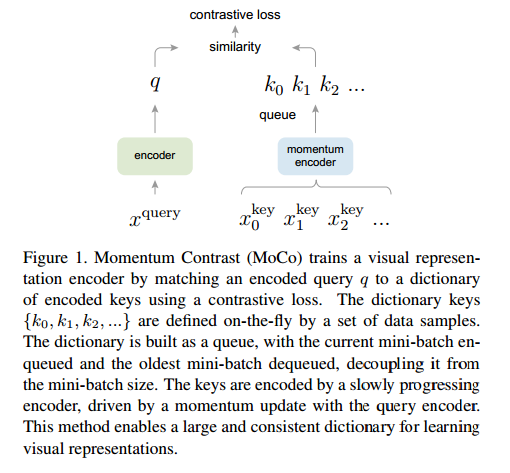
如上图所示,作者将字典表示为数据采样的队列:当前mini-batch的编码表示特征被入队,旧的mini-batch的编码表示特征被出队。队列的使用使得字典的大小和mini-batch的大小无关,因而字典可以有很大的容量;同时,字典的键值来自于先前的几个mini-batches的融合,使用查询集编码特征的基于动量的滑动平均值计算得到,保证了字典的持续性。
相关工作
无监督/自监督学习方法通常涉及两个问题:pretext tasks和损失函数。Pretext tasks表示这一任务的提出并不是为了解决某个特定的任务,而是为了学习一种好的数据表示。损失函数通常独立于pretext tasks。本文主要集中在损失函数上。
损失函数:一种常用的定义损失函数的方法是:度量模型输出和固定目标之间的差异,例如使用$L_1$或$L_2$损失对输入像素进行重构,或者使用交叉熵或margin-based损失进行分类。
对比损失(contrastive losses)被用于度量一个表示空间中的样本对的相似性。在使用对比损失时,目标可以是不固定的,可以在训练过程中实时计算产生,也可以被定义为由网络计算得到的数据表示。对比损失是近来无监督学习领域的一些工作的核心。
对抗损失(adversarial losses)度量概率分布之间的差异。该损失常被用于无监督数据生成。
Pretext tasks:有很多pretext tasks被提出,例如:在一些损坏的条件下对输入进行恢复(去噪自编码器、背景自编码器或者交叉通道自编码器);另一些pretext任务构建pseudo-labels(单张图片的转换、patch orderings、追踪或者视频目标分割、特征聚类)。
对比学习和pretext tasks:不同的pretext tasks可以基于不同的对比损失函数。
方法
使用对比学习进行字典查找
给定已经编码的查询集$q$和使用已编码的样本集合$\{k_0,k_1,…k_n\}$作为键值的字典。假设,对于$q$来说,在字典中只有单个键值$k_+$与其匹配。当$q$与其正键值$k_+$相似,而与其他键值(负键值)不相似时,对比损失具有较小的值。在本文中使用的是对比损失的一种:InfoNCE,使用点乘对相似度进行度量:
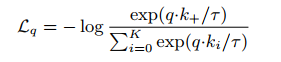
其中,$\tau$为温度超参数。
对比损失被用于无监督学习的目标函数,来训练编码器网络对查询集和键值进行表示,如:$q=f_q(x_q),k=f_k(x^k)$。其具体形式取决于具体的任务。
动量对比
将字典设计为队列的形式
字典应该是动态的、且键值由随机采样产生,键值的编码在训练过程中进行迭代。字典中的样本被持续更新,当前mini-batch被压入队列,队列中较早的mini-batch则被移除。字典总是代表着所有数据的子集。
使用动量的形式进行更新
使用队列的形式可以使得字典变得很大,但同时也使得使用反向传播更新键值编码器变得困难(每一次都需要对队列中的所有样本进行梯度反向传播)。一个简单的解决方法是直接复制查询集编码器$f_q$,用于替代键值编码器$f_k$,同时忽略梯度。但在实际中,这种方法效果不行。作者认为这是由于快速改变的编码器降低了键值表示特征的连续性,为此,提出了动量更新方法。
将键值编码器的参数表示为$\theta_k$,查询集编码器的参数表示为$\theta_q$,使用如下方式更新$\theta_k$:
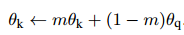
其中,$m\in[0,1)$。实验表明,较大的系数优于相对较小的系数,说明缓慢更新键值编码器很重要。
几种不同的对比损失
如下图所示:
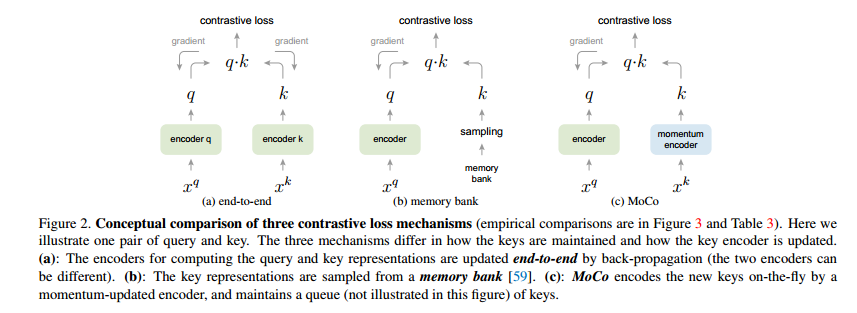
左侧第一种:使用当前mini-batch实时更新查询集编码器和键值编码器;
中间:构造memory bank,所有样本的编码特征都被存储在memory bank中;
右侧:本论文提出的方法,使用动量法实时更新键值编码器的参数。
算法流程
伪代码如下:

在上述代码中,每次迭代时,对相同的样本使用了不同的数据增强方法,将结果分别作为查询集和键值。