Learning Efficient Object Detection Models with Knowledge Distillation
这篇应该是第一篇使用知识蒸馏解决高效目标检测网络的训练问题的文章,在该文中,作者作出了以下贡献:
提出一个使用知识蒸馏和启示学习方法学习紧凑、快速目标检测网络的新框架。作者指出,尽管知识蒸馏可以提升简单的分类模型的性能,但将其应用于目标检测模型时,会面临回归、区域建议和不宽松的类标问题。为了解决这些问题,作者使用了加权交叉熵损失解决类别不均衡问题、教师边界损失解决回归问题,同时使用可调整层来更好地从教师网络的中间层分布进行学习。
内容简介
相比于分类问题,将知识蒸馏方法应用于目标检测模型时,性能会有很大的降低,有以下几点原因:
- 对类标进行检测需要更强的网络能力。
- 知识蒸馏是针对分类提出的,它的前提假设是每一类是同等重要的。但对于目标检测来说,背景类更为普遍。
- 检测任务更为复杂,需要同时处理分类和边框回归问题。
为了解决以上问题,作者提出了以下解决方法:
- 端对端可训练框架用于学习紧凑的多类别目标检测网络。
- 提出新的损失函数,使用加权交叉熵解决背景类和目标类的不平衡问题。针对知识蒸馏,提出教师边界回归损失;针对启示学习,加入可调整层,使得学生网络可以更好地从教师网络的中间层分布中学习信息。
方法
本文提出的网络训练架构如下图所示:
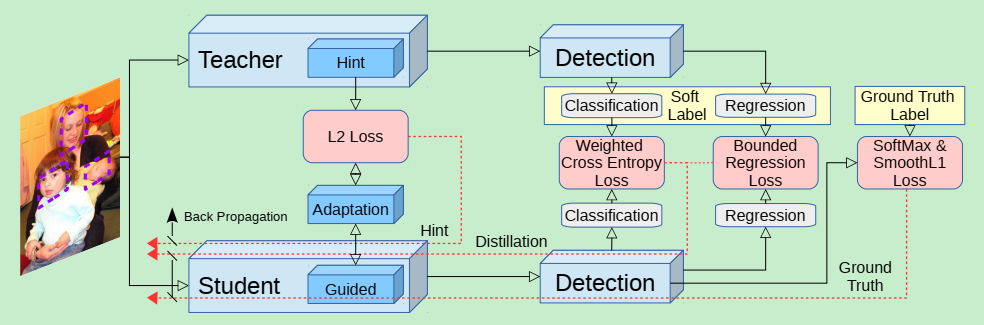
文章中使用的目标检测模型为Faster R-CNN,Faster R-CNN主要分为三部分:
- 用于提取特征图的卷积层。
- 用于给出目标建议的区域建议网络(RPN)。
- 针对每一个目标建议,给出类别分数和空间位置调整的分类和回归网络(RCN)。
为了得到高精确度的检测结果,需要对以上三个部分同时进行调整。
- 使用启示学习使得小网络的特征表示和老师网络相似;
- 使用知识蒸馏框架在RPN和RCN部分都学得好的分类网络;
- 将老师网络的回归输出作为一个上界,如果学生的回归输出比老师的好,就不计算这一部分损失。
整体损失的结构如下:
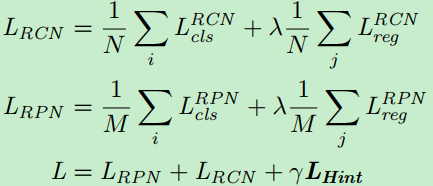
其中,类别损失$L_{cls}^{RCN}$由两部分组成,一部分是学生网络的输出与真实标定的损失,另一部分损失是与教师网络输出的损失;回归损失$L_{reg}$由平滑$L_1$损失和提出的教师边界损失组成;$L_{Hint}$表示启示损失。
针对类别不平衡问题设计的类别损失:

其中:
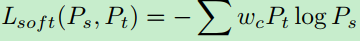
带有教师边界的回归,整体的回归损失如下:
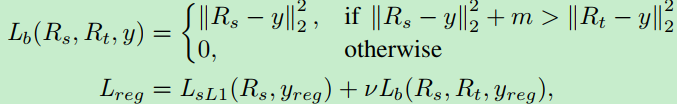
当学生网络的性能超过教师网络一定的值时,就不计算学生网络的损失。使得学生网络的回归性能接近或者优于教师网络,但一旦接近教师网络的性能,便不再过分要求。
带有特征适应的启示学习:
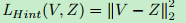
为了使得学生网络中间层的特征和教师网络中间层的特征匹配,添加了自适应层进行特征图大小的调整。
结果
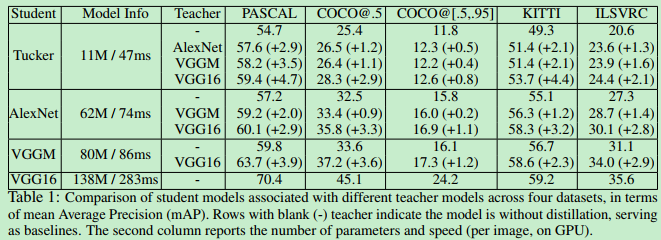
如上表所示,在加入知识蒸馏方法后,网络的性能都有了一定幅度的提升。